library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(here)Warning: package 'here' was built under R version 4.4.3here() starts at C:/Users/Zacha/github/CSU/ESS 330/ess_330_project_proposallibrary(flextable)
Attaching package: 'flextable'
The following object is masked from 'package:purrr':
composelibrary(patchwork)Warning: package 'patchwork' was built under R version 4.4.3# Create some visualizations and descriptions of what data you have, where you got it, and how and if you need to clean and manipulate it for your project
# Import data from csvs and clean NAs
parkserve_data <- read_csv(here("data", "clean_data/parkserve_summarized_facts_2020.csv")) %>%
drop_na()Rows: 100 Columns: 15
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (10): city_name, city_pop, land_area, revised_area, percent_designed_par...
dbl (5): parkland_area, designed_park_area, natural_park_area, parkland_per...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.un_land_use_data <- read_csv(here("data", "clean_data/un_land_use.csv")) %>%
drop_na()Rows: 59 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): city_name
dbl (2): mean_percent_built_open_space, mean_percent_open_space_access
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# Add columns and finish cleaning parkserve data
clean_parkserve_data <- parkserve_data %>%
mutate(
across(-city_name, ~ as.numeric(.x)), # Convert all columns to numeric except for city name
parkland_percent = parkland_percent * 100, # Convert parkland percent from ratio
# Fix design/natural park area percentage calculations
percent_designed_parks = ifelse(parkland_area == 0, NA, (designed_park_area / parkland_area) * 100),
percent_natural_parks = ifelse(parkland_area == 0, NA, (natural_park_area / parkland_area) * 100),
#New calculation for designed-natural area ratio
dn_area_ratio = ifelse(percent_natural_parks == 0, NA, percent_designed_parks / percent_natural_parks)
)
# Join data removing cities found in only one of the two datasets
urban_parks_data <- clean_parkserve_data %>%
inner_join(un_land_use_data, by = "city_name")
# Basic data structure exploration
glimpse(urban_parks_data)Rows: 25
Columns: 18
$ city_name <chr> "Anchorage, AK", "Atlanta, GA", "Boston…
$ city_pop <dbl> 299100, 498059, 687725, 2744859, 377963…
$ land_area <dbl> 1090997, 85217, 30897, 145686, 49726, 2…
$ revised_area <dbl> 1086019, 84250, 29175, 136796, 46880, 2…
$ parkland_area <dbl> 914138, 5293, 5072, 13609, 3170, 20352,…
$ designed_park_area <dbl> 2417, 3864, 2556, 8593, 1792, 10974, 40…
$ natural_park_area <dbl> 911721, 1429, 2516, 4430, 1378, 9378, 1…
$ parkland_percent <dbl> 84.173297, 6.282493, 17.384747, 9.94839…
$ percent_designed_parks <dbl> 0.2644021, 73.0020782, 50.3943218, 63.1…
$ percent_natural_parks <dbl> 99.735598, 26.997922, 49.605678, 32.551…
$ pop_density <dbl> 0.28, 5.91, 23.57, 20.07, 8.06, 6.39, 7…
$ parkland_per_1k_pop <dbl> 3056.295553, 10.627255, 7.375041, 4.744…
$ park_units <dbl> 228, 416, 373, 645, 179, 397, 302, 70, …
$ park_units_per_10k_pop <dbl> 7.622869, 8.352424, 5.423680, 2.349847,…
$ percent_half_mile_walk <dbl> 0.75091, 0.72447, 0.99790, 0.98220, 0.8…
$ dn_area_ratio <dbl> 0.00265103, 2.70398880, 1.01589825, 1.9…
$ mean_percent_built_open_space <dbl> 22.0, 13.8, 19.8, 17.2, 20.0, 20.4, 20.…
$ mean_percent_open_space_access <dbl> 71.9, 21.2, 68.2, 47.8, 29.8, 41.9, 43.…# Descriptive Stats
# Write function to round numeric columns to two decimal places
round_numeric <- function(df) {
df %>%
mutate(across(where(is.numeric), ~round(.x, 2)))
}
# Summarize stats by variable
desc_stats_parks <- urban_parks_data %>%
select(where(is.numeric)) %>%
pivot_longer(cols = everything(), names_to = "variable", values_to = "value") %>%
group_by(variable) %>%
summarize(mean = mean(value, na.rm = TRUE),
median = median(value, na.rm = TRUE),
sd = sd(value, na.rm = TRUE),
Q1 = quantile(value, 0.25, na.rm = TRUE),
Q3 = quantile(value, 0.75, na.rm = TRUE)) %>%
round_numeric()
# Print descriptive stats with flextable
desc_stats_flex <- flextable(desc_stats_parks) %>%
set_caption("Summarized Urban Parks Statistics") %>%
set_header_labels(
variable = "Variable",
mean = "Mean",
median = "Median",
sd = "Standard Deviation",
Q1 = "1st Quartile (Q1)",
Q3 = "3rd Quartile (Q3)") %>%
autofit()
# Find Top/Bottom cities for percent parkland
# Select relevant columns
simplified_vars <- c("city_name", "city_pop", "revised_area", "pop_density", "parkland_area", "dn_area_ratio", "parkland_percent", "parkland_per_1k_pop", "percent_half_mile_walk")
# Filter top/bottom 10 cities
top10_park_percent <- urban_parks_data %>%
arrange(desc(parkland_percent)) %>%
slice_head(n = 10) %>%
select(all_of(simplified_vars)) %>%
round_numeric()
bottom10_park_percent <- urban_parks_data %>%
arrange(parkland_percent) %>%
slice_head(n = 10) %>%
select(all_of(simplified_vars)) %>%
round_numeric()
# Create top/bottom 10 flextables w/ function
# Create function
make_best_worst_flextbl <-function(df, caption) {
flextable(df) %>%
set_caption(caption) %>%
set_header_labels(
city_name = "City Name",
city_pop = "City Population",
revised_area = "City Land Area (Revised) (Acres)",
pop_density = "Population Density (People/Acre)",
parkland_area = "City Parkland Area (Acres)",
parkland_percent = "Percent Parkland",
parkland_per_1k_pop = "Parkland Per (1000) Capita",
percent_half_mile_walk = "Percent of Residents within 0.5 Miles of a Park",
dn_area_ratio = "Designed-Natural Park Area Ratio (Designed Park (%) / Natural Park (%)") %>%
autofit()
}
top10_park_percent_flex <- make_best_worst_flextbl(top10_park_percent, "Top 10 Cities for Parkland Percentage")
bottom10_park_percent_flex <- make_best_worst_flextbl(bottom10_park_percent, "Top 10 Cities for Parkland Percentage")
# Make plots to visualize the data
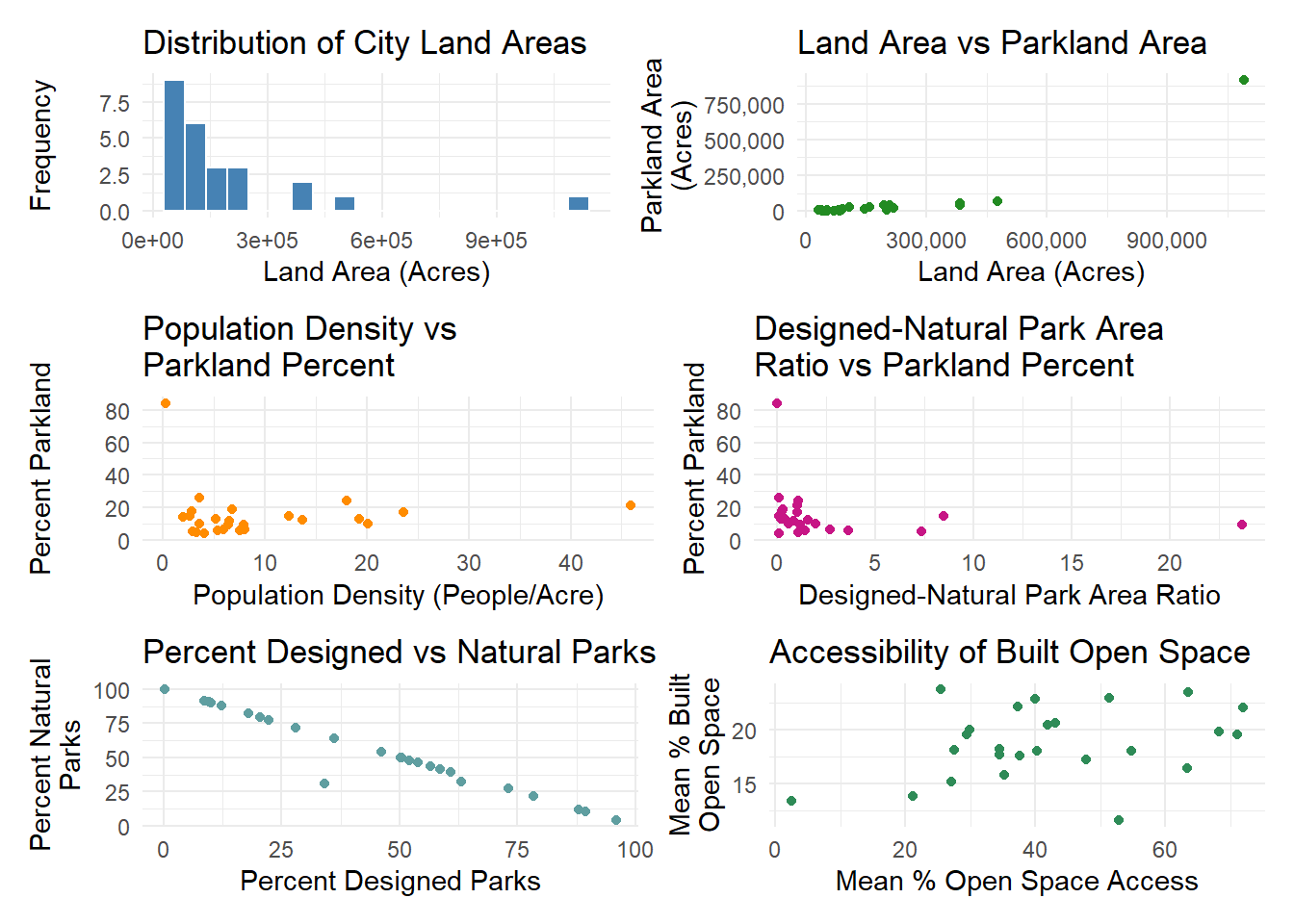
# Histogram: Land Area
land_area_plot <- ggplot(urban_parks_data, aes(x = as.numeric(land_area))) +
geom_histogram(bins = 20, fill = "steelblue", color = "white") +
labs(x = "Land Area (Acres)", y = "Frequency", title = "Distribution of City Land Areas") +
theme_minimal()
# Scatterplot: Land Area vs Parkland Area
land_vs_park_area_plot <- ggplot(urban_parks_data, aes(x = as.numeric(land_area), y = parkland_area)) +
geom_point(color = "forestgreen") +
labs(x = "Land Area (Acres)", y = "Parkland Area\n(Acres)", title = "Land Area vs Parkland Area") +
scale_x_continuous(labels = scales::label_comma()) +
scale_y_continuous(labels = scales::label_comma()) +
theme_minimal()
# Scatterplot: Population Density vs Parkland Percent
density_vs_park_percent_plot <- ggplot(urban_parks_data, aes(x = as.numeric(pop_density), y = parkland_percent)) +
geom_point(color = "darkorange") +
labs(x = "Population Density (People/Acre)", y = "Percent Parkland", title = "Population Density vs\nParkland Percent") +
scale_x_continuous(labels = scales::label_comma()) +
scale_y_continuous(labels = scales::label_comma()) +
theme_minimal()
# Scatterplot: Designed-Natural Park Area Ratio vs Parkland Percent
dn_area_ratio_vs_park_percent_plot <- ggplot(urban_parks_data, aes(x = dn_area_ratio, y = parkland_percent)) +
geom_point(color = "mediumvioletred") +
labs(x = "Designed-Natural Park Area Ratio", y = "Percent Parkland", title = "Designed-Natural Park Area\nRatio vs Parkland Percent") +
scale_x_continuous(labels = scales::label_comma()) +
scale_y_continuous(labels = scales::label_comma()) +
theme_minimal()
# Scatterplot: Percent Designed Parks vs Percent Natural Parks
designed_vs_natural_parks_plot <- ggplot(urban_parks_data, aes(x = percent_designed_parks, y = percent_natural_parks)) +
geom_point(color = "cadetblue") +
labs(x = "Percent Designed Parks", y = "Percent Natural\nParks", title = "Percent Designed vs Natural Parks") +
theme_minimal()
# Scatterplot: Percent Open Space Access vs Percent Built Open Space
open_space_access_vs_built_plot <- ggplot(urban_parks_data, aes(x = mean_percent_open_space_access, y = mean_percent_built_open_space)) +
geom_point(color = "seagreen") +
labs(x = "Mean % Open Space Access", y = "Mean % Built\nOpen Space", title = "Accessibility of Built Open Space") +
theme_minimal()
# Combine all plots in one figure using patchwork (optional)
all_eda_plots <- (land_area_plot | land_vs_park_area_plot) /
(density_vs_park_percent_plot | dn_area_ratio_vs_park_percent_plot) /
(designed_vs_natural_parks_plot| open_space_access_vs_built_plot) +
plot_layout(guides = "collect")
# Display data summary and visualization
# Display flextables
desc_stats_flexVariable | Mean | Median | Standard Deviation | 1st Quartile (Q1) | 3rd Quartile (Q3) |
|---|---|---|---|---|---|
city_pop | 1,113,559.56 | 655,061.00 | 1,696,534.55 | 377,963.00 | 1,006,142.00 |
designed_park_area | 5,559.20 | 3,864.00 | 5,020.97 | 2,652.00 | 5,785.00 |
dn_area_ratio | 2.42 | 1.02 | 4.90 | 0.26 | 1.56 |
land_area | 178,285.40 | 88,800.00 | 224,466.29 | 53,723.00 | 201,635.00 |
mean_percent_built_open_space | 18.71 | 18.20 | 3.23 | 17.20 | 20.60 |
mean_percent_open_space_access | 42.06 | 40.00 | 17.04 | 29.80 | 52.80 |
natural_park_area | 48,113.72 | 4,538.00 | 180,621.84 | 1,429.00 | 22,527.00 |
park_units | 460.80 | 302.00 | 811.06 | 179.00 | 416.00 |
park_units_per_10k_pop | 4.55 | 4.54 | 1.72 | 3.28 | 5.42 |
parkland_area | 53,824.36 | 9,478.00 | 180,158.96 | 5,075.00 | 28,312.00 |
parkland_per_1k_pop | 143.17 | 12.09 | 607.26 | 9.15 | 28.14 |
parkland_percent | 15.31 | 12.54 | 15.58 | 6.76 | 17.38 |
percent_designed_parks | 44.66 | 50.28 | 27.85 | 20.43 | 60.90 |
percent_half_mile_walk | 0.76 | 0.80 | 0.20 | 0.63 | 0.96 |
percent_natural_parks | 53.78 | 49.61 | 28.29 | 32.55 | 79.57 |
pop_density | 9.52 | 6.39 | 9.84 | 3.59 | 12.41 |
revised_area | 175,389.60 | 87,844.00 | 222,631.64 | 52,765.00 | 196,098.00 |
top10_park_percent_flexCity Name | City Population | City Land Area (Revised) (Acres) | Population Density (People/Acre) | City Parkland Area (Acres) | Designed-Natural Park Area Ratio (Designed Park (%) / Natural Park (%) | Percent Parkland | Parkland Per (1000) Capita | Percent of Residents within 0.5 Miles of a Park |
|---|---|---|---|---|---|---|---|---|
Anchorage, AK | 299,100 | 1,086,019 | 0.28 | 914,138 | 0.00 | 84.17 | 3,056.30 | 0.75 |
New Orleans, LA | 386,105 | 107,655 | 3.59 | 27,775 | 0.11 | 25.80 | 71.94 | 0.80 |
Washington, DC | 702,321 | 38,955 | 18.03 | 9,478 | 1.09 | 24.33 | 13.50 | 0.98 |
New York, NY | 8,627,852 | 187,946 | 45.91 | 40,190 | 1.01 | 21.38 | 4.66 | 0.99 |
San Diego, CA | 1,399,844 | 205,918 | 6.80 | 39,385 | 0.29 | 19.13 | 28.14 | 0.81 |
Virginia Beach, VA | 457,832 | 159,341 | 2.87 | 28,312 | 0.26 | 17.77 | 61.84 | 0.68 |
Boston, MA | 687,725 | 29,175 | 23.57 | 5,072 | 1.02 | 17.38 | 7.38 | 1.00 |
Honolulu, HI | 1,006,142 | 379,885 | 2.65 | 57,141 | 0.09 | 15.04 | 56.79 | 0.79 |
Minneapolis, MN | 421,339 | 33,958 | 12.41 | 5,075 | 8.47 | 14.94 | 12.04 | 0.98 |
Jacksonville, FL | 925,142 | 467,298 | 1.98 | 67,707 | 0.14 | 14.49 | 73.19 | 0.35 |
bottom10_park_percent_flex City Name | City Population | City Land Area (Revised) (Acres) | Population Density (People/Acre) | City Parkland Area (Acres) | Designed-Natural Park Area Ratio (Designed Park (%) / Natural Park (%) | Percent Parkland | Parkland Per (1000) Capita | Percent of Residents within 0.5 Miles of a Park |
|---|---|---|---|---|---|---|---|---|
Durham, NC | 275,758 | 68,678 | 4.02 | 2,665 | 0.11 | 3.88 | 9.66 | 0.51 |
Memphis, TN | 655,061 | 196,098 | 3.34 | 9,194 | 1.10 | 4.69 | 9.15 | 0.46 |
Winston-Salem, NC | 248,839 | 83,917 | 2.97 | 4,263 | 7.34 | 5.08 | 17.13 | 0.37 |
Detroit, MI | 660,960 | 87,844 | 7.52 | 5,102 | 3.63 | 5.81 | 7.72 | 0.80 |
Toledo, OH | 277,467 | 51,169 | 5.42 | 3,175 | 1.41 | 6.20 | 11.44 | 0.81 |
Atlanta, GA | 498,059 | 84,250 | 5.91 | 5,293 | 2.70 | 6.28 | 10.63 | 0.72 |
Cleveland, OH | 377,963 | 46,880 | 8.06 | 3,170 | 1.30 | 6.76 | 8.39 | 0.83 |
Dallas, TX | 1,378,903 | 215,676 | 6.39 | 20,352 | 1.17 | 9.44 | 14.76 | 0.71 |
St. Louis, MO | 310,144 | 39,090 | 7.93 | 3,749 | 23.66 | 9.59 | 12.09 | 0.98 |
Chicago, IL | 2,744,859 | 136,796 | 20.07 | 13,609 | 1.94 | 9.95 | 4.74 | 0.98 |
# Display patchwork plots
all_eda_plots